Systems for providing the cooling of air or liquids when supplied with a source of heat such as from a solar collector.
Contents:
Also: Homes@ +, Cooling@, Heating@
The standard method is to use
PV panels
to generate electricity which is used to power a standard AC system
Pros:
Cons:
See also:
Another natural form of air conditioning / ventilation is to use the solar heat to evacuate the hot air from a house, and cause cool air to be drawn in from an earth tube. Note that the cooling effect is actually provided by the thermal mass of the earth around the tube; the sun is simply pumping the air. This technique was used or invented by the Romans a long time ago.
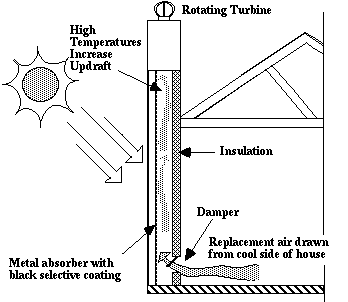 How it works: the sun heats up the chimney causing the air inside
to rise, thus drawing air through the cool pipe. The pipe cools the air drawn
from the outside to the temperature of the earth at the depth at which it
is buried (which is virtually constant year around at this depth). By the
way, an interesting note: Even in cold climates where the ground is frozen,
the incoming air is only 32F when the air outside may be much colder, we
need only heat the air by 38F to bring it to 70F; as opposed to heating outside
air of say -15F to 70F we would have to heat the incoming air by 85F - quite
a difference in the amount of heating energy we would have to supply by some
other means.
How it works: the sun heats up the chimney causing the air inside
to rise, thus drawing air through the cool pipe. The pipe cools the air drawn
from the outside to the temperature of the earth at the depth at which it
is buried (which is virtually constant year around at this depth). By the
way, an interesting note: Even in cold climates where the ground is frozen,
the incoming air is only 32F when the air outside may be much colder, we
need only heat the air by 38F to bring it to 70F; as opposed to heating outside
air of say -15F to 70F we would have to heat the incoming air by 85F - quite
a difference in the amount of heating energy we would have to supply by some
other means.
Of course, without the sun to warm the chimney (or some other source) the system isn't worth fooling with. Other possible replacements for the chimney are Whole House Fans.
A few points:
1. Surface area, NOT size. It does no good to dig a 10 foot diameter tunnel since the air in the center is insulated from the cooling effect of the tunnel wall.
2. Maintenance will be required. Animals, weeds, roots and all other manner of bad things will happen.
I would (have not yet) find an area near the space to be cooled which slopes away (for drainage) and then dig a pattern of deep pits, like fox holes. I would then use an auger to dig horizontally (slightly down slope) between the pits and line the holes with sections of metal pipe assembled in the pits. The pits would then be covered with an insulating material which can easily be removed to allow access to the pipe segments for cleaning or clearing with a rag tied to the top of a flexible pole.
The ideal landscape in which to install such a system would be a something like the side of an overturned bowl. Imagine cooking a chocolate cake in a shallow bowl, then emptying it out onto a platter. Built your house at the top and then cut small pie shaped sections every few inches around the cake, but remove only the top half of each cut section and then only back into the mound a short distance. Now, push soda straws between the cut out sections, near the bottom of the cut so that they are linked around the side of the mound. Remove all but the shell of the sections you cut out and use them to cover the openings so that the ends of the straws are still open, but the air will not be able to leave the overall straw system. At the end, use a bendable straw to direct the air up to the house on top and the solar tower.
If you can't find that terrain, you might be able to get away with long metal tubes, very gently curved and buried with a ditch digger so that both ends are above ground. Small drainage holes will need to be drilled along the lowest point of the pipe and gravel or other darning system installed at the bottom of the ditch before the pipe is laid in. Connections between pipe segments would be made with a manifold or other plumbing above ground and should be well insulated. Cleaning or maintenance would require the disassembly of the manifold so some form of normally covered opening on the opposite side of the manifold from each pipe could be a very helpful addition. Easy to install, maintain and provides a large surface area of contact between the ground and the air.
At the worst, if you can dig any sort of a ditch and connect both ends of the buried pipe back into the home, you can run a rope through the pipe to form a loop. Sponges, towels or other cleaning devices can be attached to the rope and then pulled through the pipe. As long as the rope doesn't break...
Find more at http://www.google.com/search?hl=en&q=earth+cool+pipe+OR+tube
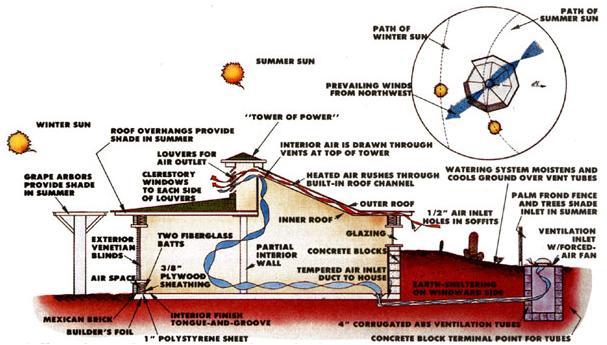
See also:
Also:
A good idea:
Why not combine a chimney and a cooling tower? One outer shell of thermally transparent material, inside that, a heat exchanger to transfer radient solar energy into the air, then an insulative layer and finally, a cooling tower with some combination of water mist, evaporative pads, or thermal conductors driven into the ground.
I had a crazy idea some time ago, about using a small, cheap solar collector to produce superheated steam (and my father and I did build the device described up to this point and it worked just fine) and then use a venturi to trade the velocity of escaping steam for volume of air moved (inject steam via a fine pitot into the opening of a pipe so that outside air is pulled into the pipe) [ed: better yet, use the steam jet to create a vacumn in the exit pipe on the hot side and avoid the temp increase of the steam on the inlet side] and then direct that into a Hilsch Vortex tube to produce hot/cool air for house A/C.
I would guess that back pressure at the entrance to the Vortex would limit the incoming air volume excessively or that the increased temp of the air (due to the steam injection) would negate any cooling gains on the part of the Vortex or some such other problem would prevent it from working. The nice thing would be: No moving parts other than the water and the air and the collector (sun tracking), automatically starts when the sun heats it up, super low construction cost, almost zero operating cost (only maintenance and water supply). The potential inefficiencies are offset by the low (zero) cost of water and sunlight.
Russell McMahon commented:
Use of steam for refrigeration was a standard technique early this century. AFAIR, steam was expanded through a nozzle and drew air from a venturi tube (?) creating a low pressure region with accompanying cooling. Old or complete air conditioning books would cover this - I have only seen it described once.The advantage is, as you note here, that you can convert available thermal energy into cooling. Also, there are no moving parts. You could also consider using a "kerosene fridge" type arrangement which uses heating to drive an adsorption cycle using, typically, ammonia and water. Only moving parts here are the fluid(s). This may be easier as the technology is current and common and you could copy an existing fridge or use an existing one and simply heat the appropriate point.
Hilsch Vortex / Wiebel Rohr / Maxwell's ... typically seems to like around 100psi (7 bar / 700 kilopascal) but lower should work with suitable "design".
commented
Steam-jet refrigeration is still used to concentrate fruit juices and similar temp sensitive substances. There is a Scientific American article about construction of a Vortex tube, circa late '50s, early 60's... Mo' high-tech: http://www.sunpower.com
Annie Ogborn says:
...Randy Hees at Ardenwood Historic Farms (infoseek search results) in [Fremont near] Newark, CA. The farm and the Society For the Preservation of Carter Railroad Resources are some of the most knowledgeable people in the country about obsolete technologies. Randy Hees is pres. of SPCRR.Another good resource is the Society for Industrial Archeology's skills preservation section. [see vol. 16 no 1 for "Artificial Refrigeration and the Architecture of 19th-Century American Breweries," Susan K. Appel, 16, 1(1990):21-38]
Russell McMahon describes another system that he has uncovered...
It relies on what is termed an "ejector" or "steam ejector" or a thermodynamic compressor. These terms are in fairly standard use.Steam from a highish pressure source is expanded through a diverging nozzle and then run on through a longer converging section. The pressure drops in the initial section and then rises again to a lower level. At the lowest pressure point (at the end of the initial expansion section) a hole is placed which enters into a chamber.
The result is to lower the pressure of the attached chamber and entrain any vapour from this chamber into the expanding and contracting steam. The drop in pressure in the chamber causes vaporisation of the water in the chamber to produce cooling.
Systems I have seen described recently said that a steam pressure of about 10 bar is typically used and that the steam vaporised is about 20% of the total vaporisation. ie about 4 times as much vapour is derived from the chamber as comes from the steam boiler.
I have mentally designed a really cheap solar collector using concrete, re-bar, hose clamps, a huge stack of razor blades, a small compressed air tank, sheet metal and the 1 foot square decorator mirrors found at any home supply. Tools are: two steel pins cast in concrete to use as a re-bar bending tool, a bench vice with the jaws widened by a pair of steel bars to bend the sheet metal, a cut off tool (air or electric drill powered), and the normal screwdriver, etc... Several lengths of re-bar are bent like:
__ __ | |______________| |
The ends are sharpened to a chisel point (cut off tool) and rest in groves on concrete pads at either end. Attach guy wires from the center span to the high points to prevent flexing, but do that after the mirrors are mounted. They will now rock side to side with little pressure. A connecting rod is fashioned to connect the high points on one end or the other together so that an actuator may position the array to point to the sun. The sheet metal is cut into strips about 6" wide and 18" long and bent into the following shape:
_ _ \ / \^/
with a small slot cut near the bottom of the lower bend for the hose clamp to pass through. They are clamped along the re-bar. Spread the top open, insert a decorator mirror and let go. This clamps the mirror. Loosen the hose clamp, align the mirror holder so that all the mirrors point back to a common point centered above the collector.
At this focal point, rests a boiler on a mast of two pipes (water in, steam out).
Bolt the stack of razors together with two long very high test bolts. Use big very high test washers on either end. Vice them so that the edges are PERFECTLY aligned. Tighten them with breaker bars till you are sweating and the heads and nuts round off then tighten them some more. Smooth any irregularities along the sides of the stack.
Cut a slot in the end of the air tank just the width of the stack of razor blades and cut two holes for the pipes and one for a pop-off valve. Take the blades, pipes, and tank to your local welding shop and challenge them to weld the stack into the slot (I know it can be done, I've seen it, wrapping the stack in super thin steel foil helps) and the pipes into the holes so that one is almost to the top and the other is near the bottom. Also weld on the pop-off valve (a mother big chunk of steel with a 1" hole in one end that rests over a short length of pipe with a cap that has a small hole in it; remember pressure cookers?). Pressure test the boiler professionally. This boiler will work very well. Nothing transfers heat into water like a stack of razor blades.
We need a small (very high pressure) water injection pump, a sun tracking actuator, and maybe a better pop off valve. I can't remember how the injection pump knows when the boiler needs water.
See also:
Patents:
Questions:
Another issue is one of condensation and moisture in the pipe. That can lead to mold and serious health problems. To prevent it, the air inlet of the tube must be at the low point and there has to be a steady slope all the way down so the condensate can drain. This is hard to ensure with a coiled pipe.
In your case, it would be easier just to vent from your basement up into the house. The air between the house and the earth is probably several degrees cooler.+
| file: /Techref/other/spac.htm, 23KB, , updated: 2020/3/11 06:39, local time: 2025/5/21 00:59,
18.222.132.108:LOG IN
|
| ©2025 These pages are served without commercial sponsorship. (No popup ads, etc...).Bandwidth abuse increases hosting cost forcing sponsorship or shutdown. This server aggressively defends against automated copying for any reason including offline viewing, duplication, etc... Please respect this requirement and DO NOT RIP THIS SITE. Questions? <A HREF="http://www.sxlist.com/techref/other/spac.htm"> Solar powered Air Conditioning</A> |
| Did you find what you needed? |
Welcome to sxlist.com!sales, advertizing, & kind contributors just like you! Please don't rip/copy (here's why Copies of the site on CD are available at minimal cost. |
|
Ashley Roll has put together a really nice little unit here. Leave off the MAX232 and keep these handy for the few times you need true RS232! |
.